
- Decoding Natural Language Processing (NLP) before the Transformer model
- Predecessors of the AI Transformer model: RNNs, LSTM Networks, and CNNs
- Breaking down the Transformer neural network
- Let’s see another example of how Transformers work
- So, what is the use of Transformer model development architecture in ChatGPT?
- Wrapping up
 Share It On:
Share It On:
Transformers, a type of neural network architecture adopted by OpenAI for its language models, are witnessing a boom in popularity. The invention of transformers was done to solve the problem of sequence transduction or neural machine translation. They are used in any model that translates inputs into outputs. Transformers are now witnessing a huge boom in their popularity as the underlying algorithm for Natural Language Processing (NLP) due to their amazing capabilities. Recently, OpenAI and AlphaStar also adopted AI Transformer models and used them in their language models. Adopting Transformer model development has revolutionized the ability of chatbots to translate, understand sentiments, generate texts, and more compared to the traditional approach of responding to inputs.
The best potential of Transformers can be experienced in ChatGPT models by OpenAI, LaMDA, and in even the popular open-source model BigScience Large Open-science Open-access Multilingual Language Model (BLOOM).
Moving forward, in this blog, we will break down the AI Transformer model development to understand its way of functioning in-depth. But first, we will start with understanding Natural Language Processing (NLP) model to figure out What is AI Transformer model’s role in making NLP and AI chatbots more efficient and capable. Let’s begin!
Decoding Natural Language Processing (NLP) before the Transformer model
Before feeding any text to a neural network, the input gets transformed into a set of numbers. This process of transforming inputs into numbers is known as embedding. The transformed version of the input, however, does not lose its original characteristics, such as the emotion of the text, the relationship of words with each other, etc. To answer what is Natural Language Processing (NLP), in simple terms, it is an interdisciplinary subfield of linguistics, computer science, and artificial intelligence used to make chatbots sound more humane.
The model is designed to give computers the strength to understand, speak, and remember spoken or written words. NLP is a fusion between deep learning, machine learning, statistical models, that enables understanding of the human languages.. The technology helps any computer understand the sentiment of a text and even helps computers to connect multiple segments of conversations with each other to respond more humanlike. Currently, NLP has become popular in the global AI chatbot industry and brands are looking forward to adopting this technology as soon as possible.
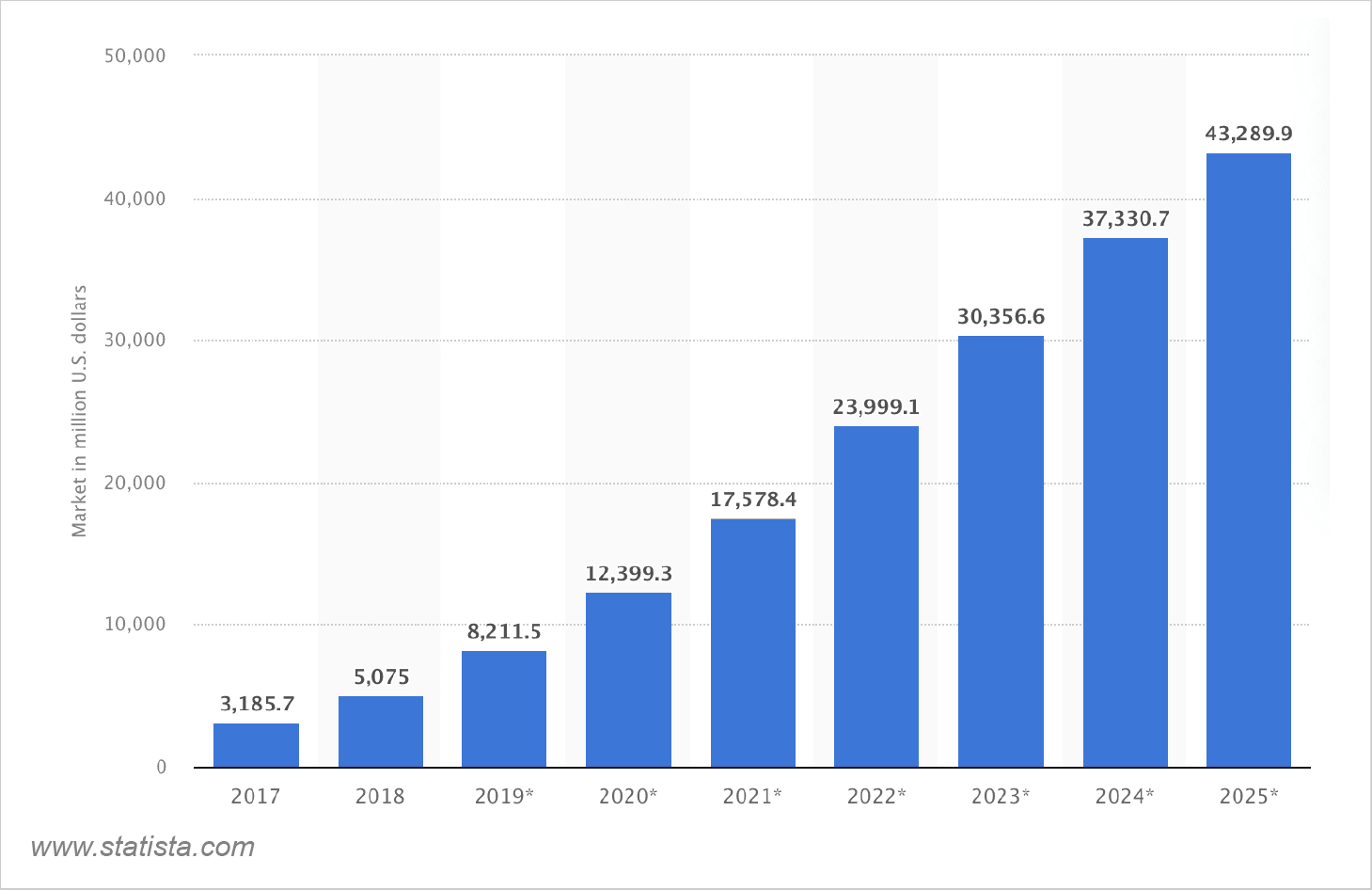
The image above by Statista is evidence of NLP’s growing popularity. From approx $3 billion in 2017 to $43 billion in 2026, NLP is expected to have a 14x larger market coverage by the end of 2026.
Predecessors of the AI Transformer model: RNNs, LSTM Networks, and CNNs
Now, before Transformer neural networks became a thing, there were Recurrent Neural Networks (RNNs), Long Short Term Memory Networks (LSTM Networks), and Convolutional Neural Networks (CNNs) that powered NLP models.
Recurrent Neural Networks (RNNs)
RNNs are designed as a part of artificial neural networks to process sequential data. RNNs retain the information every time they process any input, which helps them answer new inputs better. Every time a new input is received by the network, this information is updated with new data to retain and that is how the model that uses RNN keeps improving with time as it understands the user better. RNNs are capable of capturing long-term sequences using patterns and relationships between words.
Long Short-Term Memory (LSTM) Networks
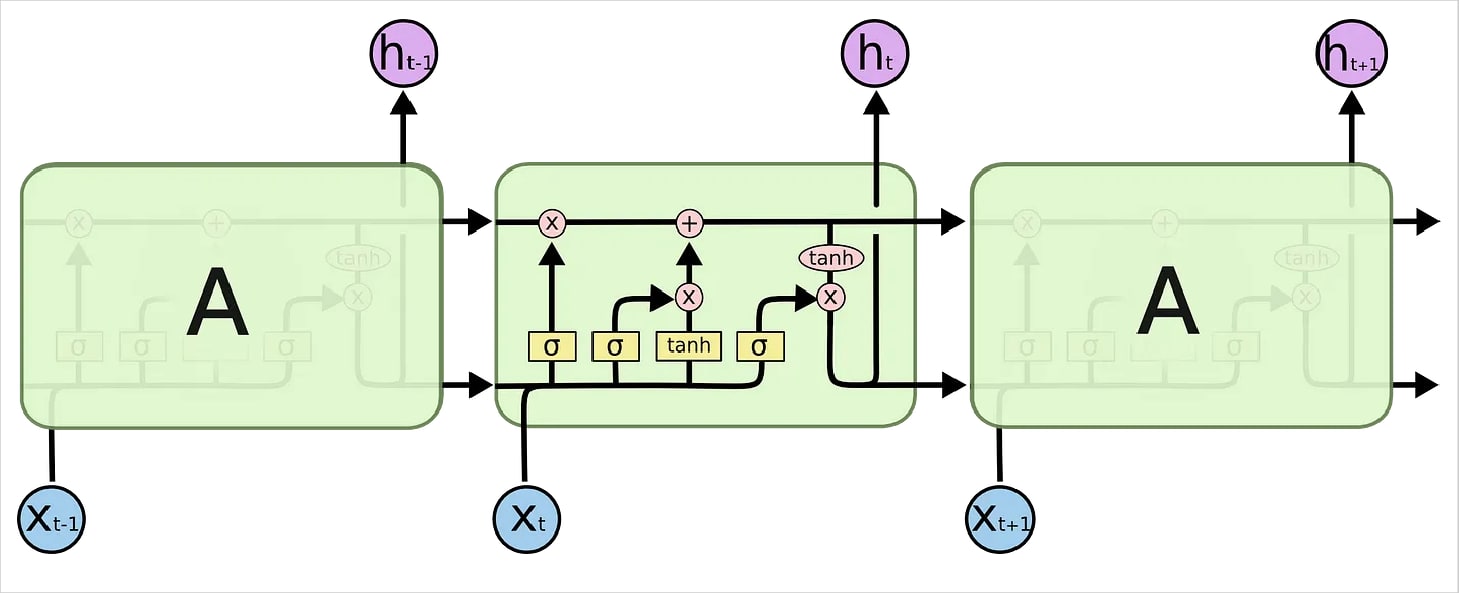
A variant of RNNs, LSTM networks are incorporated with memory cells and gating mechanisms. Using memory cells, LSTM networks are able to remember information in long sequences making them able to keep up with a continuous conversation.
The image above from Towards Data Science explains it sophisticatedly. The input information goes through the memory cell where it is transformed and remembered before processing the output. The memory cell picks the information that is worth remembering and uses it to manipulate the next set of inputs if there is a relationship between words.
To break down properly, the LSTM model includes three gates:
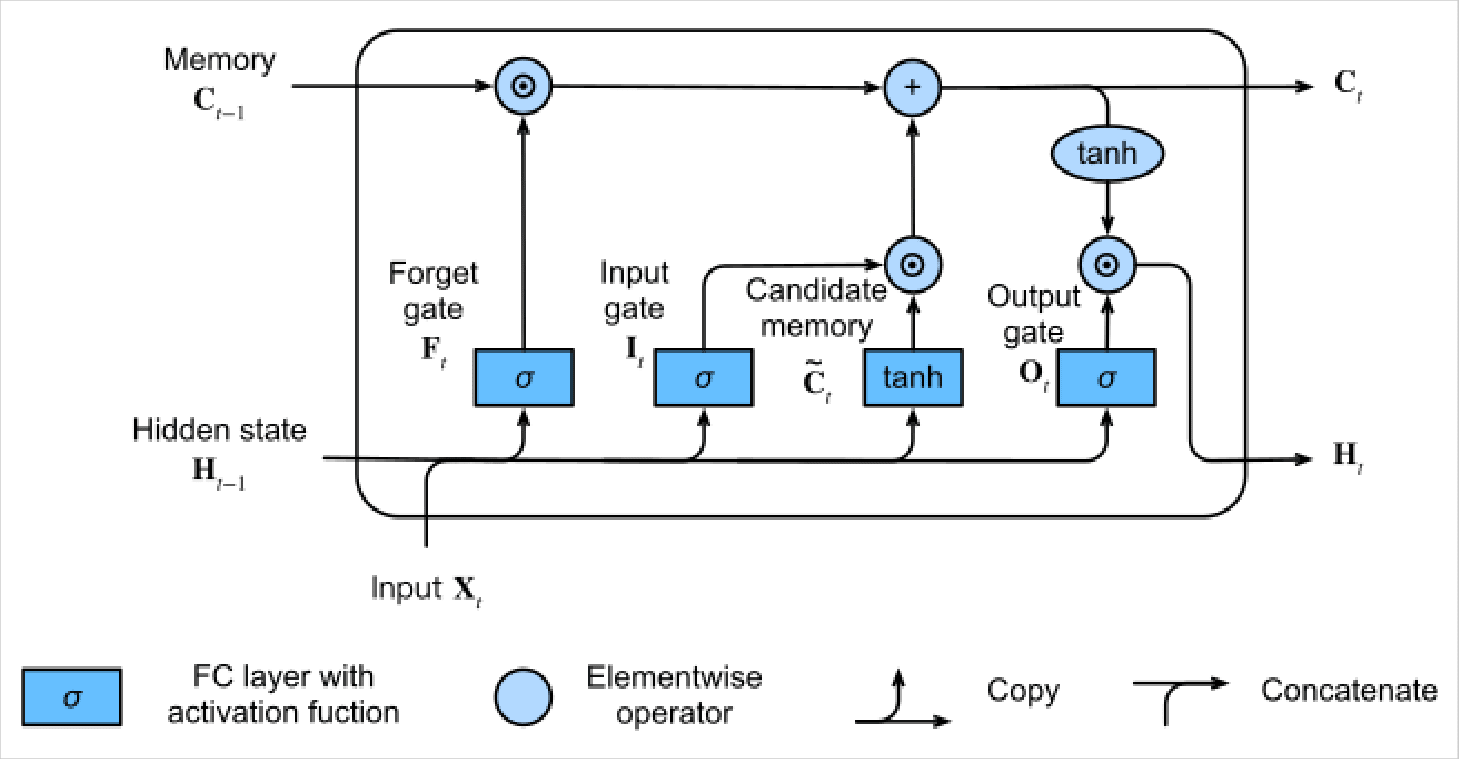
- The input gate to receive the data;
- Forget gate to regulate the data and decide when and what to remember or forget;
- The Output gate then extracts the response.
Convolutional Neural Networks (CNNs)
CNNs are popular for their ability to classify texts and analyze sentiments accurately. The model was also popular for parallel processing of data using convolutional filters. However, it faced challenges in capturing global dependencies and handling long sequences.
Breaking down the Transformer neural network
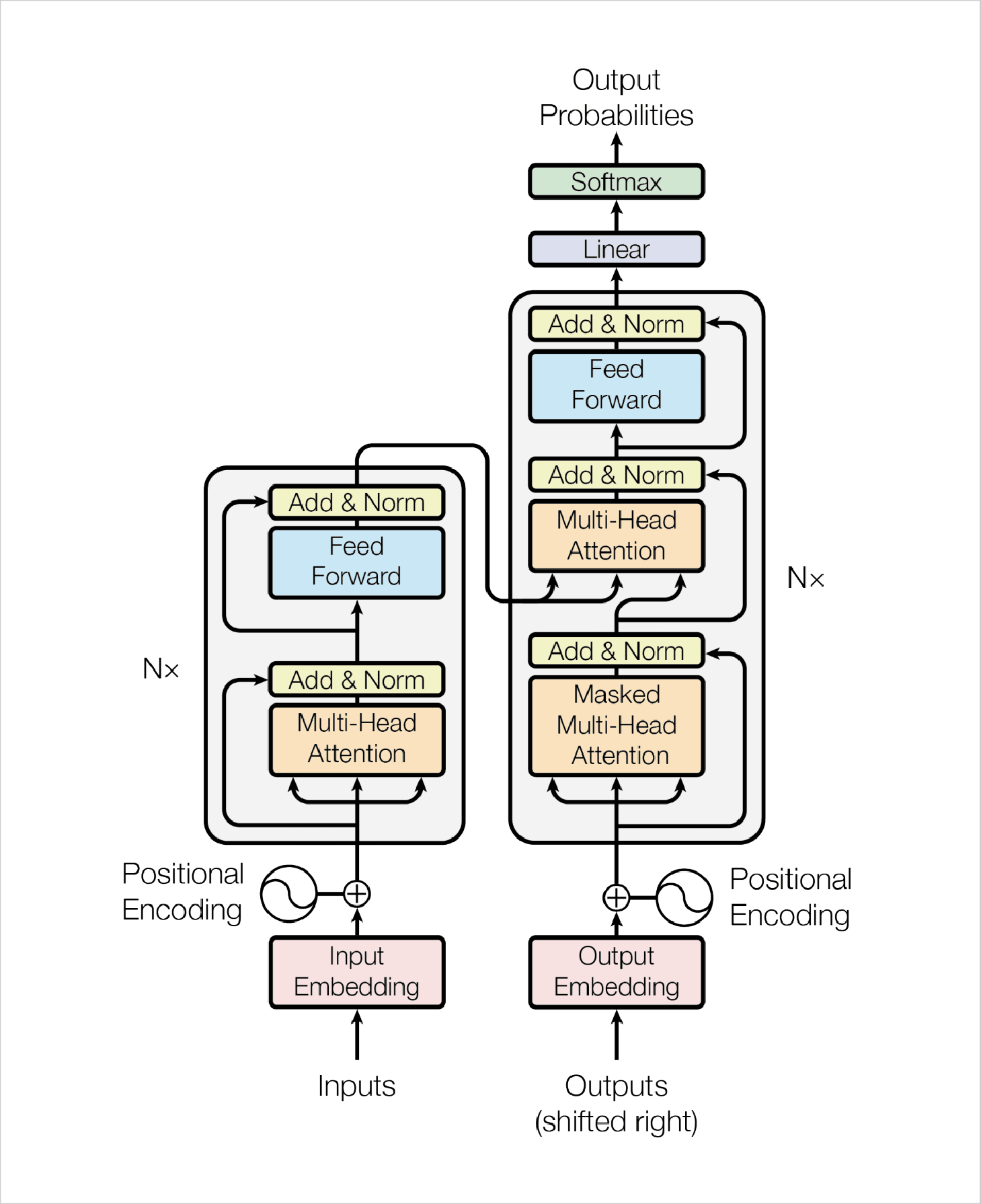
Now, let’s break down the Transformer architecture further and discuss it in-depth. The above image published in a paper titled Attention Is All You Need represents the Transformer model machine learning process well. The image covers the workflow of Transformers, representing each and every part of the module that is involved in the Transformer’s deep learning process.
To break it down further, you will have to focus on the left blue block and the right blue block as Encoders and Decoders. Transformers use Encoders to find relationships between words in an input. Now by using Attention, it adds weight to each word of the sentence and extracts it to another layer for output embedding. In parallel, Decoders pick the processed result, add weight to each word, and then combine the result.
Let’s see another example of how Transformers work

Generally, Transformer’s deep learning architectures include 6 Encoders and 6 Decoders. All Encoders in the AI Transformer model development architecture have the same structure. In every Encoder, there are two layers: Forward Neural Network and Self-attention. Decoders, on the other hand, share the same property and are quite similar to each other but not exactly the same as Encoders.
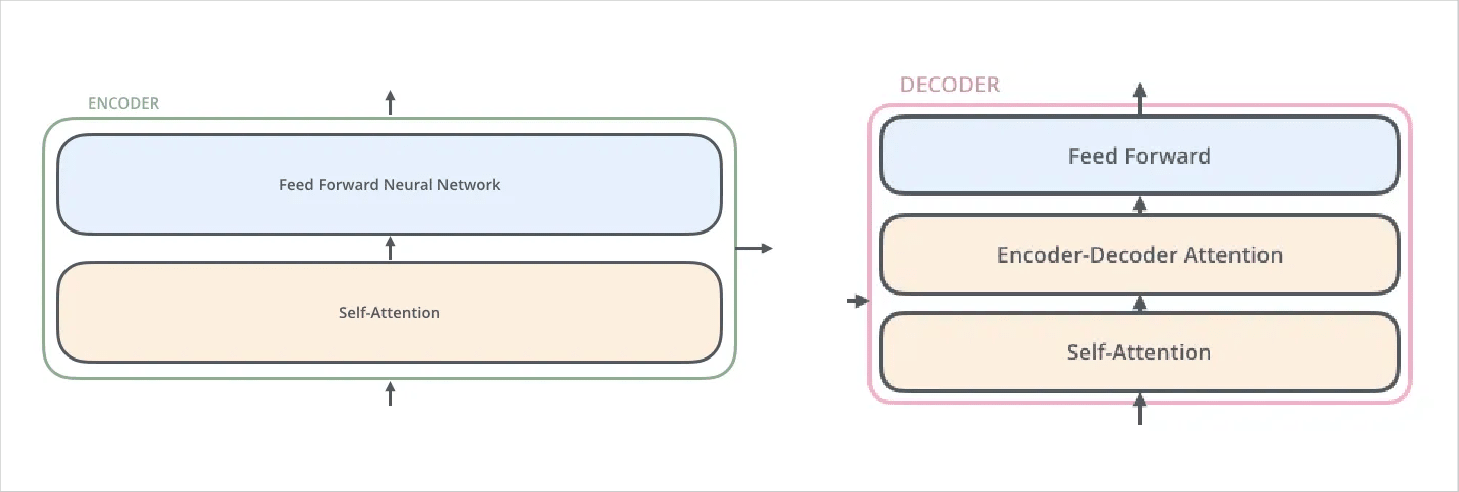
Attention
Another key element of the Transformer model machine learning architecture is Attention. It refers to the exact process as it sounds. For instance, when you read something, you focus on a specific word to understand what it represents, and as you keep reading, you keep focusing on separate words in a sequence, or if you are watching a movie, you pay attention to each scene.
That is how Attention in neural networks works as well. Artificial intelligence development companies have been using Attention to help neural networks focus on specific parts of information shared with them. Attention is used in neural networks to focus on each hidden meaning in every word involved in an input. This helps the model in generating more precise responses.
Self-attention
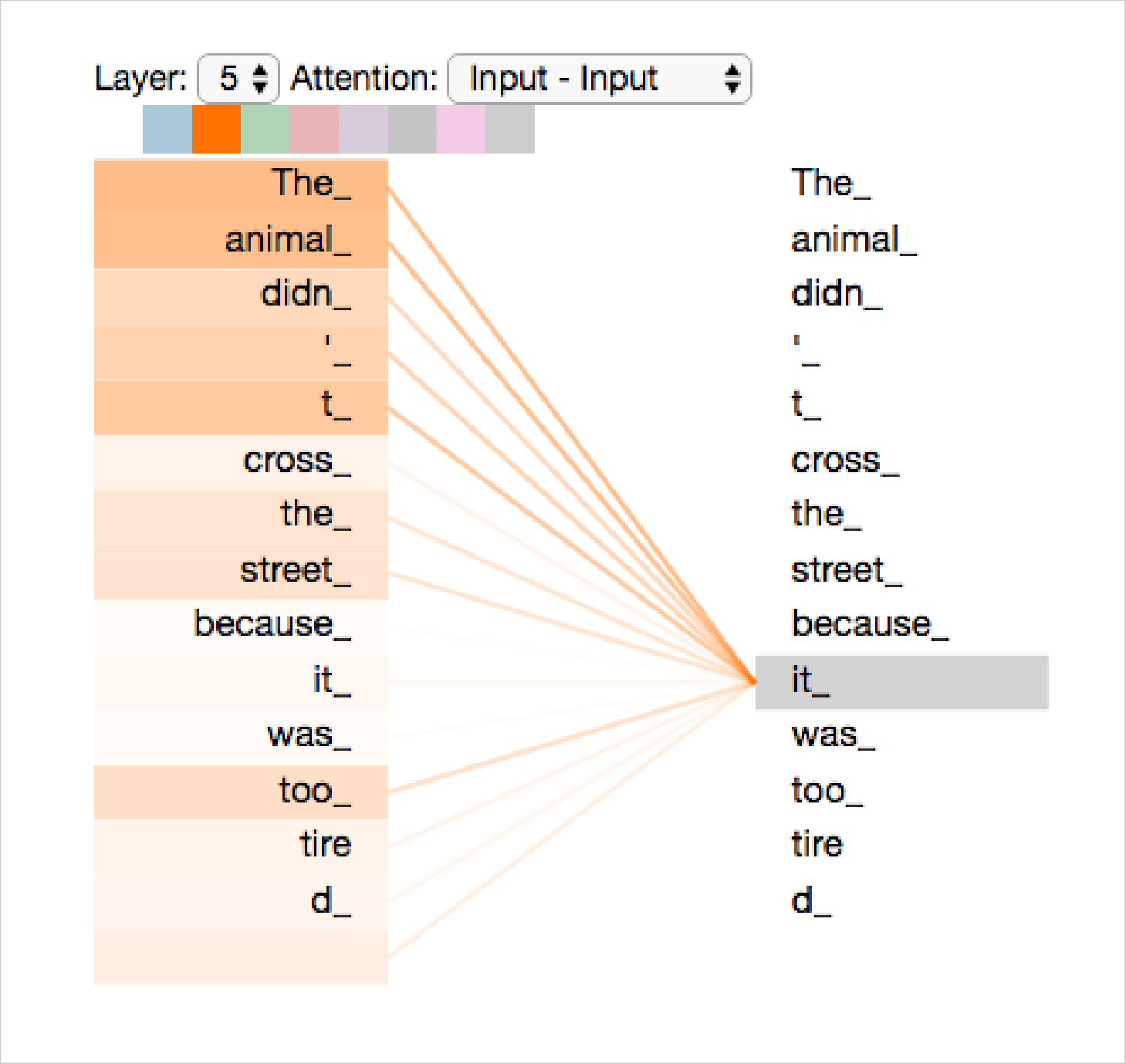
Anytime Encoders receive any input, these inputs first go through the self-attention layer. The layer encodes a specific word in the input, while the encoder can pay attention to other words. Once processed, it generates outputs that are fed to Feed-forward neural networks. The attention layer of the Decoder helps it focus on only relevant information that came as inputs.
This example by Jalam Mar explains the process of Selt-attention better. This method of AI Transformer model development demonstrates that while the Transformer model is processing each word in the input sequence, self-attention lets it focus on other words as well to find more words for better and more precise encoding.
To calculate self-attention, each word is assigned a Query vector, a Key vector, and a Value vector. Then comes the second step which is calculating the score and assigning the score to each word so the amount of focus can be determined by the model.
Now comes the third step, which includes dividing the score by the square root of the dimension of the key vectors. And the result will be passed through a Softmax operation as the fourth step. The fifth step is to multiply each value vector by the softmax score, and the sixth step is to sum up the weighted value vectors. These steps conclude the calculation of the Self-attention process.
Multihead attention
The Transformer model machine learning architecture also cares about observing multiple details for more accurate outputs. This model can pay attention to different words at once to find out the relationships between them, their meanings, etc.
Position Encoding
This encoding step is done to determine the position of each word in input and output to keep the sequence of results correct.
So, what is the use of Transformer model development architecture in ChatGPT?
ChatGPT is loved due to not one but multiple reasons, for instance, the ability to process instant responses, and that too while sounding like a real human. For Natural Language Processing (NLP), the machine learning Transformer architecture helps the model generate more accurate responses. Here’s how Transformer's deep learning makes it possible:
1. Self-attention mechanism: The part of the Transformer model machine learning architecture that we discussed above helps ChatGPT understand relationships between words in an input sequence. It enables us to figure out dependencies between words and find long-range associations between them.
2. Encoder-Decoder Architecture: The Transformer architecture of ChatGPT includes an Encoder and a Decoder as well. The Encoder receives and processes the input message while the Decoder instantly starts working on the response.
3. Parallel Processing: To leverage the Transformer’s ability to process multiple inputs in parallel is also a reason why it was picked for ChatGPT. This ability of the machine learning Transformer architecture helped generate responses faster.
4. Pre-training and Fine-tuning: The Transformer model development helps ChatGPT finetune inputs using the pre-training and training data for better quality results. The pre-training phase helps the model to understand the language and sentiments better.
Wrapping up
The abilities of the AI Transformer model helps ChatGPT become more intuitive and intelligent. The purpose of this article is to explain how the Transformer model is contributing to making ChatGPT a reliable tool. As ChatGPT 3, 3.5, and 4 are trained with a massive amount of data that existed on the internet, in books, publications, and in other such sources, AI models such as Transformer are able to leverage this massive data for better optimization of the tool.
At the time of writing this blog, ChatGPT has two versions of its release for people. ChatGPT 3.5 which is updated with the data until 2021, and ChatGPT 4 which is updated with more amount of data and covers events that happened post-2021 as well. It also offers support for image generation. However, ChatGPT 3.5 is free, while GPT 4 is a paid tool.
GPT-4 is said to be more improved in terms of dialogues, responsiveness, data accuracy, etc. The Transformer model development approach leverages more parameters from ChatGPT 4’s server and offers better accuracy.
“We spent 6 months making GPT-4 safer and more aligned. GPT-4 is 82% less likely to respond to requests for disallowed content and 40% more likely to produce factual responses than GPT-3.5 on our internal evaluations.”
- OpenAI authors
Frequently Asked Questions
How does the self-attention mechanism work in the Transformer model?
How is the Transformer model applied in natural language processing tasks?
What is a transformer model in NLP?
What type of model is a transformer?

Uncover executable insights, extensive research, and expert opinions in one place.



